DLQ for AWS StepFunctions
What is DLQ?
DLQ is a concept widely used in message queues, for example, in AWS SQS. Basically, DLQ is a queue to collect the messages that can’t be processed successfully. When you see that your DLQ received some messages, you understand that processing has failed for some messages from the main queue. With that knowledge you can analyze these messages using application logs, traces and metrics and decide how to fix the issue. When you think the issue is fixed, you can move messages from the DLQ to the main queue and reprocess them. Or discard them, depends on your needs. You can read more about DLQ for AWS SQS here.
Why does AWS StepFunctions lack DLQ?
AWS StepFunctions executions can be started via AWS EventBridge, in this case StepFunctions execution acts as an event consumer. But what if the execution fails during the processing? It’s possible to configure an alarm to get a notification for failed executions but when you resolve the issue, you can’t easily restart all the failed executions because they are no longer present as events.
You can restart them manually but when there are hundreds of them, it’s not what you want to do. Having the data about failed executions in some queue would solve the issue with restarting them.
Approach 1. EventBridge (CloudWatch Events) for Step Functions execution status changes
StepFunctions execution status change is an event that can be processed via AWS EventBridge. The following rule catches all failures of StepFunctions executions:
{
"source": ["aws.states"],
"detail-type": ["Step Functions Execution Status Change"],
"detail": {
"status": ["FAILED", "TIMED_OUT"],
"stateMachineArn": ["ARN"]
}
}All these events can be collected in a queue and then sent to reprocessing via Lambda function.
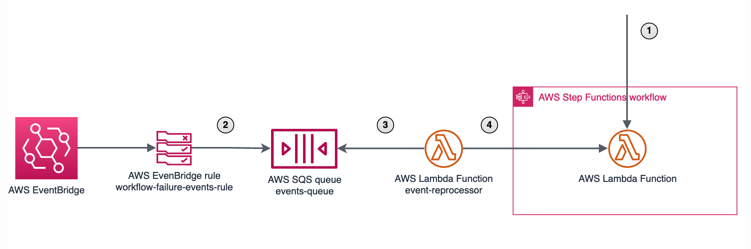
- Some input event starts a new StepFunctions execution. Execution fails.
- Execution state change event is sent to an SQS queue via EventBridge rule.
- Lambda function reads the messages from the queue.
- Lambda function starts new StepFunctions executions.
Approach 2. Catching StepFunctions errors
Briefly this approach described on StackOverflow.
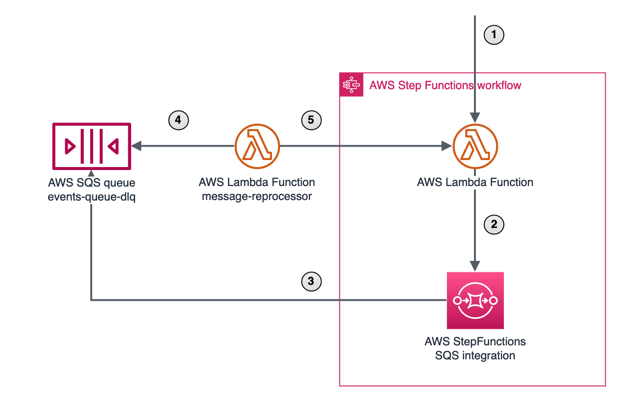
Here you can see a DLQ to collect the failed messages and a lambda function to restart the StepFunctions. Let’s see what happens here step by step:
- Some input event starts a new StepFunctions execution.
- Executions fails, the error is caught by the StepFunctions and the workflow is moved to the catch state.
- Catch state is an SQS integration state that sends a message with the execution input (using execution context expression
$$.Execution.Input) to a standalone queue. - Lambda function reads the messages from the queue.
- Lambda function starts new StepFunctions executions.
Moreover it can be combined with the catch-all approach described here to catch errors from all the states using only one catch block. The resulting StepFunctions definition looks like this:
Show StepFunctions definition JSON
{
"StartAt": "ParallelState",
"States": {
"ParallelState": {
"Type": "Parallel",
"Branches": [
{
"StartAt": "Lambda",
"States": {
"Lambda": {
"Type": "Task",
"Resource": "ARN",
"End": true
}
}
}
],
"Catch": [
{
"ErrorEquals": [ "States.ALL" ],
"Next": "Send to DLQ"
}
],
"Next": "Success"
},
"Send to DLQ": {
"Type": "Task",
"Resource": "arn:aws:states:::sqs:sendMessage",
"Parameters": {
"QueueUrl": "URL",
"MessageBody.$": "$$.Execution.Input",
"MessageAttributes": {}
},
"Next": "Fail"
},
"Success": {
"Type": "Succeed"
},
"Fail": {
"Type": "Fail"
}
}
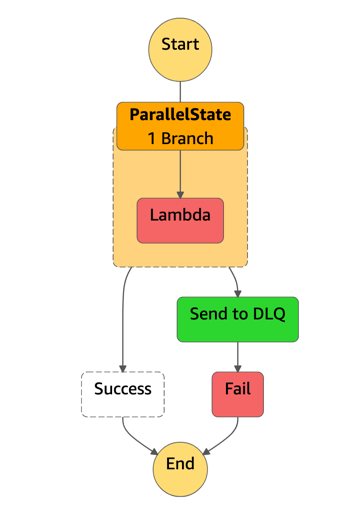
}The execution will look like this in case of error (Fail state is added to make the whole execution failed, otherwise it will be reflected as a successful execution because the error is caught):
Which approach to use?
From my perspective the first approach looks cleaner as it doesn’t require any changes in the StepFunctions definitions and all errors are handled on a higher level. But there can be some cases when the second approach is more suitable. For example, if you need to start reprocessing from a particular state and not from the default state. In this case you can customize the message sent to SQS with the catch state to include additional information about the failed state and about the error. And then you can use this information to navigate the state machine to the desired state after restart using Choice states. This case is described in AWS Compute Blog.